Live Document Hub
Automated monitoring of policy developments for real-time journalism
I developed the Live Document Hub as a core feature of Borderlex's Datahub, solving a critical challenge for trade policy journalists who previously had to manually monitor dozens of institutional websites daily. The system now automatically tracks and aggregates document releases from approximately 50 key institutions, including EU bodies, government ministries, international organizations, and think tanks. This automation has enabled Borderlex journalists to discover time-sensitive documents quickly, leading to breaking news coverage that would have been missed or delayed through manual monitoring.
Technical Architecture and Implementation
I designed and built a comprehensive automated data collection process using Python libraries for web scraping and other data ingestion tasks. The pipeline integrates multiple data sources through web scraping, RSS feeds, and institutional APIs, handling diverse data formats including XML and JSON.
To ensure data reliability in the notoriously volatile web environment, I implemented a flexible architecture using Pydantic (a Python library for data validation) that automatically validates incoming data and adapts to changes in the data sources without requiring extensive code modifications. This validation framework has proven essential for maintaining data quality across the varied institutional sources.
I orchestrate the data pipeline using Dagster, enabling automated scheduling and monitoring. All collected data is stored in a PostgreSQL database enhanced with full-text search capabilities, optimized for the text-heavy nature of policy documents.
User Interface and Experience
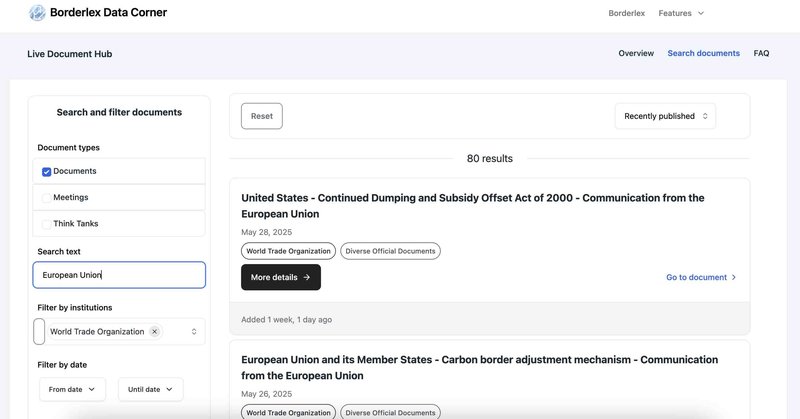
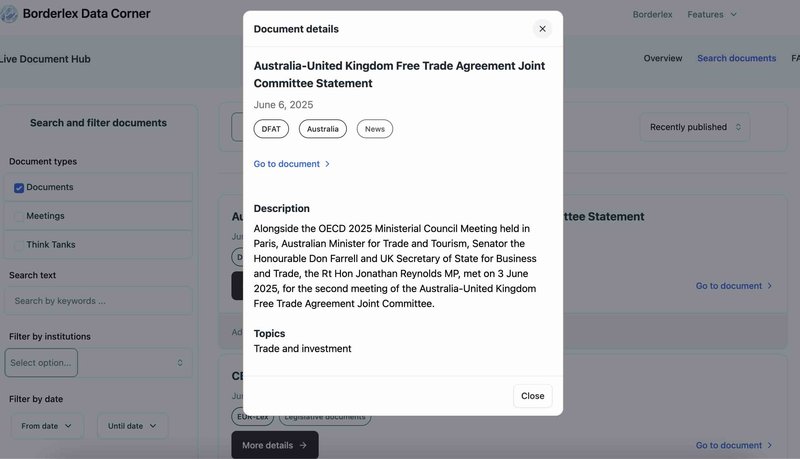
I built the user-facing interface as part of a Django web application, creating an intuitive document stream that displays the most recently published materials. The interface includes advanced search and filtering capabilities, allowing journalists to quickly locate specific documents or narrow results by institution, date, or topic. I integrated HTMX to create responsive, interactive components that enhance the user experience.
Content Quality and Curation
Working closely with Borderlex's editorial team, I implemented a targeted content curation strategy based on expert-selected institutional sources. This collaboration ensured the system captures the most relevant and authoritative sources for trade policy reporting.
To further enhance content quality, I developed and trained a custom text classification model using a dataset combining Borderlex content with public policy documents. I implemented a Logistic Regression classifier with TF-IDF text vectorization using scikit-learn, achieving an F1 score above 0.90. Crucially, I optimized the model to minimize false negatives—ensuring relevant documents are never missed—while accepting some false positives to maintain comprehensive coverage. This approach successfully filters out irrelevant content while maintaining fast processing speeds and ensuring no important policy developments slip through the system.
Impact and Results
The Live Document Hub has transformed Borderlex's research workflow by eliminating the need for manual monitoring of 50+ institutional websites. Journalists report discovering unexpected, newsworthy documents through the system that directly contributed to timely story publication. The automated monitoring ensures comprehensive coverage that would be impossible to maintain manually, while the intelligent filtering keeps the content feed focused and actionable.