Amendment Tracker
Gain insights into the evolution of legislative texts
Trade journalists and policy professionals were spending countless hours manually searching through scattered PDF documents to track legislative amendments in the European Parliament. The Amendment Tracker, developed as part of the Datahub platform, eliminates this bottleneck by transforming unstructured documents into an intuitive, searchable platform that streamlines access to critical legislative information.
The tracker covers the election periods from 2019 to today, processing approximately 4,500 PDF documents and close to 50,000 individual amendments submitted by all MEPs who held seats during this time. It comes in two specialized versions: one focused on amendments submitted in the Committee on International Trade, where most legislative work takes place, and another for plenary amendments related to trade policy.
This project demonstrates end-to-end data engineering capabilities, from PDF processing and NLP model deployment to full-stack web application development and system administration.
Technical Implementation
Challenge: Extracting structured data from inconsistent PDF layouts
Parliamentary amendment documents follow established formatting conventions, but their implementation varies due to human error, typos, and occasional deviations from standard templates across the 4,500+ document corpus.
Solution: Robust parsing pipeline with validation
I built Python-based PDF parsing tools that identify patterns in both text content and document layout, accommodating format irregularities while maintaining extraction reliability. The pipeline employs Pydantic for data validation, ensuring consistent output structure across the entire document collection. All processing tasks are organized through a command-line interface built with Typer.
Challenge: Making amendments searchable beyond simple keyword matching
Traditional text search fails to capture the nuanced policy positions and thematic connections within legislative amendments.
Solution: Semantic search with advanced NLP
I implemented semantic search capabilities using Sentence Transformers (SBERT) for generating embeddings that capture both keywords and phrase meaning. This enables users to analyze the motivations behind amendments and identify policy positions, such as finding amendments that favor or oppose specific trade measures, even when different terminology is used.
Features and Functionality
The extracted data preserves all information necessary to reproduce the official amendment format—the familiar two-column layout with original text on the left and amended version on the right. The Amendment Tracker replicates and enhances this format by highlighting metadata linked to each amendment, including MEP names with their political group and country affiliation.
Beyond visual improvements, the platform enables sophisticated analysis through linked European Parliament data. Users can search and filter amendments across multiple dimensions, including complete amendment histories for individual MEPs across parliamentary terms.
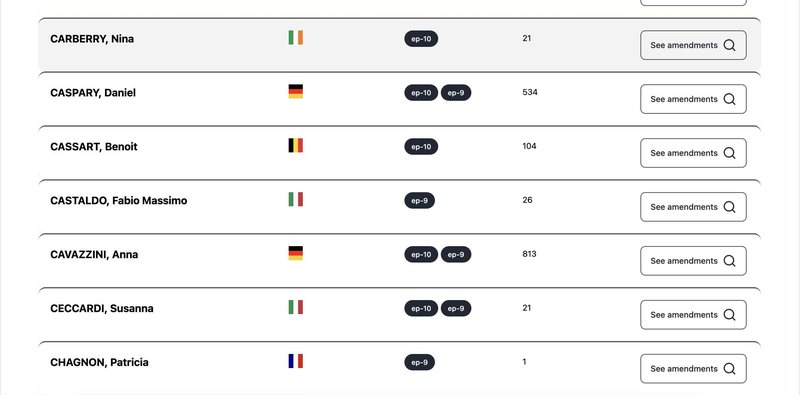
The semantic search functionality allows users to conduct thematic analysis of legislative positions, going beyond surface-level keyword matching to understand policy intent and alignment.
Technical Architecture
The Amendment Tracker is deployed as part of the Borderlex Datahub using Docker containers on a self-managed Linux virtual machine. The system uses Dagster to run the data pipeline, managing dependencies between different data sources, scheduling updates, and preparing the data for the user interface. The user interface is served via the Django-based Datahub platform enhanced with HTMX for dynamic interactions. The embedding model for semantic search, served via a FastAPI endpoint, runs as a containerized service.