Working with data from official providers: a brief tour of pandaSDMX
Dec. 13, 2023
I have always been an avid user of official statistics. Eurostat, the OECD, the World Bank, other international organisations and national statistics agencies such as the French INSEE are valuable sources of data. In this post, I present a simple and efficient way of interacting with data from these official providers.
International API standards for statistical data exchange: SDMX
All of these organisations typically provide user interfaces with search, visualisation and other functionalities to explore their databases and download data files. However, there are more productive ways to explore and obtain data. Statistical organisations provide Application Programming Interfaces (APIs) allowing users to access data programmatically and to automate work flows. The days of managing local directories littered with manually downloaded csv files are long gone.
These APIs are built around international standards. An important one to know is SDMX, which stands for Statistical Data and Metadata eXchange. SDMX is sponsored by several international organisations, such as the Statistical Office of the European Union (Eurostat), the United Nations Statistics Division (UNDS) and the Bank of International Settlements (BIS). At the core of SDMX is its information model, a definition of objects describing data and metadata, as well as their relationships. SDMX comes in different formats, one of them being SDMX-ML, which uses the XML syntax.
How to work with SDMX using Python?
If you are new to SDMX, sifting through the API documentation of the organisation in which you are interested is a good start. But it can also be a heavy read. Fortunately, the Python ecosystem offers solutions that make using SDMX relatively easy.
pandaSDMX is a Python library that enables users to access data form national statistical agencies, central banks, and international organisations via the SDMX standard. As the name suggests, pandaSDMX is closely related to the pandas library. Query results for data or metadata can easily be converted to pandas objects and handled in a way that is familiar to Python developers.
An example: obtaining data from Eurostat
Let’s work through a simple example. We will use pandaSDMX to get data from Eurostat. As a topic, we use some data coming from the EU’s annual survey on how households and individuals use Information and Communication Technologies (ICT). To reproduce the example, you can find the notebook with the code in the Github repository of my blog here.
Setting up pandaSDMX
pandaSDMX can be installed via conda (as done for the example in my repository) or pip. We also install matplotlib for this demonstration.
Once everything is installed, we can import pandaSDMX and matplotlib and get started.
import pandasdmx as sdmx
import matplotlib.pyplot as pltConnecting to a data source
Next, we choose a data provider to which we want to connect. In pandaSDMX, this is called the data source. The pandaSDMX documentation has a list of data sources, i.e. organisations that provide SDMX-based APIs. We pick Eurostat as our data source and use the string ID "ESTAT" to connect.
estat = sdmx.Request('ESTAT')We can now use the estat object to make data and metadata queries.
Searching dataflows
Now that we have a client for the Eurostat SDMX web service, we can investigate what data is available. Data is organised in dataflows. A dataflow can comprise multiple data sets that are structured in a similar way.
We could use the Eurostat user interface in the browser to search for the ID of the dataflow in which we are interested, and directly query this ID. Instead, we use pandaSDMX to get a complete overview of the dataflows available.
flow_msg = estat.dataflow()This can take a couple of seconds ... The query returns a Message instance.
<pandasdmx.StructureMessage>
<Header>
id: 'DF1702481952'
prepared: '2023-12-13T16:39:12.076000+01:00'
sender: <Agency ESTAT>
source:
test: False
response: <Response [200]>
DataflowDefinition (7537): MAR_MP_AM_CFT MAR_MP_AM_CFTT MAR_MT_AM_CSV...
DataStructureDefinition (7143): MAR_MP_AM_CFT MAR_MP_AM_CFTT MAR_MT_A...The tag shows that we are looking at a StructureMessage (in contrast to a DataMessage).
As we can see from the number next to DataflowDefinitions, we have received structural information about all dataflows (more than 7000) because we did not specify an ID for a specific dataflow.
We can already see some of the dataflow ID attributes. For example, we can inspect flow_msg.dataflow.MAR_PA_QM_PT:
<DataflowDefinition ESTAT:MAR_PA_QM_PT(1.0): Passengers (excluding cruise passengers) transported from/to the main ports - Portugal - quarterly data>This is not yet what we are looking for. So let’s do a more systematic search. The to_pandas method of the pandaSDMX package comes in handy. We are going to use it not only to convert our final data into pandas series or dataframes, but also to explore metadata.
Note that the to_pandas method can be used in two different ways: first, as a function belonging to the sdmx namespace (sdmx.to_pandas(data)), in which case the data is passed as the first argument to the function. Second, as a method of a message class (flow_msg.to_pandas()), in which case the first argument is self.
This is how we convert the message from above into a pandas series:
dataflows = sdmx.to_pandas(flow_msg.dataflow)Inspecting the type of dataflows shows that we are dealing with a pandas Series:
type(dataflows)pandas.core.series.SeriesThese are the first entries in the series:
dataflows.head()MAR_MP_AM_CFT Passengers (excluding cruise passengers) trans...
MAR_MP_AM_CFTT Passengers (excluding cruise passengers) trans...
MAR_MT_AM_CSVI Country level - number and gross tonnage of ve...
MAR_PA_AA Passengers embarked and disembarked in all por...
MAR_PA_QM Passengers (excluding cruise passengers) trans...
dtype: objectWe can use the pandas string methods to filter the results and narrow down the search. Being familiar with the EU’s ICT survey, we know that there are data on how individuals use the Internet. So this is a way to find exactly what we are looking for:
internet_use_flows = dataflows[
dataflows.str.contains('Individuals using the internet', case=False)
]We get the following output when we look at internet_use_flows:
TIN00094 Individuals using the internet for sending/rec...
TIN00095 Individuals using the internet for finding inf...
TIN00096 Individuals using the internet for buying good...
TIN00098 Individuals using the internet for selling goo...
TIN00099 Individuals using the internet for internet ba...
TIN00101 Individuals using the internet for seeking hea...
TIN00102 Individuals using the internet for looking for...
TIN00103 Individuals using the internet for doing an on...
TIN00127 Individuals using the internet for participati...
TIN00129 Individuals using the internet for taking part...
dtype: objectWe find ten dataflows about how individuals use the Internet. Let’s pick the one about internet banking. It has the ID 'TIN00099'. We can use the ID to query this dataflow directly and investigate its metadata.
Investigating the structure of a dataflow
Again, we use the dataflow method of the estat client, but this time we indicate the dataflow ID we just found:
tin_msg = estat.dataflow('TIN00099')Here is the StructureMessage:
<pandasdmx.StructureMessage>
<Header>
id: 'DF1702041294'
prepared: '2023-12-08T13:14:54.798000+00:00'
sender: <Agency ESTAT>
source:
test: False
response: <Response [200]>
Codelist (6): FREQ INDIC_IS UNIT IND_TYPE GEO OBS_FLAG
ConceptScheme (1): TIN00099
DataflowDefinition (1): TIN00099
DataStructureDefinition (1): TIN00099The message indeed contains a DataflowDefinition with the requested ID. So we can extract the dataflow from the message:
tin_flow = tin_msg.dataflow.TIN00099The next step is to understand the form of the data. The dataflow is associated with a Data Structure Definition (DSD) that we can access with the structure attribute.
dsd = tin_flow.structure
dsd<DataStructureDefinition ESTAT:TIN00099(34.1): TIN00099 data structure>The dsd object contains metadata that describe the data in the ‘TIN00099’ flow. Most importantly, we get information about dimensions, attributes and measures.
dsd.dimensions.components[<Dimension freq>,
<Dimension indic_is>,
<Dimension unit>,
<Dimension ind_type>,
<Dimension geo>,
<TimeDimension TIME_PERIOD>]For the online banking data, we have six dimensions:
freq: frequence, i.e. the interval of the observations (annual, hourly, etc).indic_is: indicators on the information society, i.e. a set of available indicators related to this dataflowunit: for instance, total number of people or percentind_type: do we talk about all individuals or some subset defined by age group or some household characteristic?geo: geopolitical entity (countries, the EU, subnational entities such as regions)TIME_PERIOD: temporal interval for which an observation is measured (e.g. year)
We can dive deeper into these dimensions by looking at the codelists associated with each of the dimensions.
cl_freq = dsd.dimensions.get('freq').local_representation.enumerated
cl_freq<Codelist ESTAT:FREQ(3.2) (11 items): Time frequency>The 11 items in the codelist tell us what options we have for querying data by time frequency. If we convert the frequency code list into a pandas series, we get the following:
name parent
FREQ
P Pluri-annual FREQ
A Annual FREQ
S Half-yearly, semesterly FREQ
Q Quarterly FREQ
M Monthly FREQ
W Weekly FREQ
B Daily - business week FREQ
D Daily FREQ
H Hourly FREQ
I Irregular / A-periodic FREQ
NAP Not applicable FREQWe should investigate the codelists carefully before querying the data. They help us to find the keys with which to target precisely the data we want to obtain.
Coming back to the dsd object, we still have to take a look at the attributes and measures.
dsd.attributes.components[<DataAttribute OBS_FLAG>]We only have one attribute: OBS_FLAG. It stands for special markers that can be added to observations, for example it can flag an observation as „not applicable“ or „provisional, Eurostat estimate“.
dsd.measures.components[<PrimaryMeasure OBS_VALUE>]Finally, we get the primary measure, i.e. information about the main thing being measured by the observation values. Digging deeper into this object shows, for example, that the measure is of type double.
Getting the actual data
Now we can query the data. Using the structural information, we can specify the portions of the data that are relevant to us. We do this by defining keys and parameters informed by the dimensions and code lists we have explored before.
We add the dictionaries key and params to our data query in order to filter the data in the following way:
key = dict(
freq="A", indic_is="I_IUBK", unit="PC_IND",
geo="DE+FR+EE+PL+RO"
)
params = dict(startPeriod='2011', endPeriod='2022')We want annual data (freq). indic_is refers to Eurostat indicators relative to the information society (IS), in our case internet banking: 'IUBK‘. The unit PC_IND stands for percent of individuals. With the key for geo we limit the data to some countries we want to compare (German, France, Estonia, Poland, and Romania). Finally, we include a dictionary with parameters. We indicate that we want data from 2011 to 2022.
data_msg = estat.data('TIN00099', key=key, params=params)This part can be a bit tricky. Not all options from the code lists of the various dimensions can actually be used in our specific data set. For example, we have to know beforehand that we work with annual data and that hourly data is not available for the share of individuals using the internet for online banking. If you define a key with options that are not available, pandaSDMX will give you a generic client error message.
You have to figure out what keys can be used to filter the data. Ideally, we could use constraints defined in the metadata. This is handled differently depending on the data source. In general, having some prior knowledge of the data you are querying is helpful to select sensible filter keys.
We can inspect attributes of the response, such as the headers and the url of our query.
data_msg.response.headers['content-type']'application/vnd.sdmx.genericdata+xml;version=2.1'data_msg.response.url'https://ec.europa.eu/eurostat/api/dissemination/sdmx/2.1/data/TIN00099/A.I_IUBK.PC_IND..DE+EE+FR+PL+RO?startPeriod=2011&endPeriod=2022'Our query worked well and we have got a DataMessage as a response.
<pandasdmx.DataMessage>
<Header>
extracted: '2023-12-13T10:15:14.435000+00:00'
id: '21212EEF50234E8BBDF01C8E1CF02DEC'
prepared: '2023-12-13T10:15:14.435000+00:00'
sender: <Agency ESTAT>
source:
test: False
response: <Response [200]>
DataSet (1)
dataflow: <DataflowDefinition (missing id)>
observation_dimension: <TimeDimension TIME_PERIOD>The DataMessage contains a data set (more specifically, a list with one GenericDataSet object). We save it in this data variable:
data = data_msg.data[0]The data comes in series. One series per country.
len(data.series)5The series have keys that correspond to the ones we used to filter the data.
data.series.keys()dict_keys([<SeriesKey: freq=A, indic_is=I_IUBK, unit=PC_IND, ind_type=IND_TOTAL, geo=DE>, ...])The data also contains observations (data.obs). Observations correspond to cells in a data table. We have 12(years) * 5(countries) - 1 (missing data) = 59 observations.
We have everything we need to convert the final data into a pandas dataframe.
If we just use the line data_df = data_msg.to_pandas(), we will get a pandas series with all of the dimensions crammed into a MultiIndex.
Instead, we can do the following:
data_df2 = sdmx.to_pandas(
data,
datetime={
'dim': 'TIME_PERIOD',
'freq': 'freq',
'axis': 1
}
)This time we get a dataframe with the years as columns in a PeriodIndex.
Now, there is only a little bit of cleaning in the index left. The indic_is, unit, and ind_type do not add much information to the index as they each can only take on one value. We just want to keep the countries in the index and the years in the columns. We achieve this by simple pandas dataframe manipulation.
data_final = data_df2.xs(
key=("I_IUBK", "PC_IND", "IND_TOTAL"),
level=("indic_is", "unit", "ind_type")
)
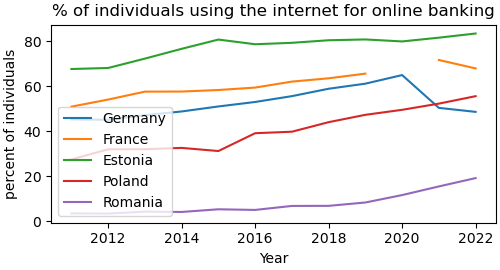
print(data_final)TIME_PERIOD 2011 2012 2013 2014 2015 2016 2017 2018 2019 \
geo
DE 45.25 45.07 47.12 48.76 50.98 52.97 55.56 58.84 61.10
EE 67.59 68.06 72.22 76.56 80.67 78.59 79.23 80.36 80.72
FR 50.90 54.04 57.56 57.60 58.28 59.36 62.01 63.48 65.55
PL 27.46 31.96 32.01 32.59 31.20 39.11 39.77 44.01 47.27
RO 3.51 3.45 4.30 4.16 5.34 5.06 6.83 6.87 8.36
TIME_PERIOD 2020 2021 2022
geo
DE 64.91 50.35 48.58
EE 79.84 81.51 83.36
FR NaN 71.60 67.86
PL 49.49 52.24 55.55
RO 11.65 15.49 19.19Analysing and visualising the data
We see the data as expected, with the one missing value for France in 2020. At this stage, we can handle the data using the familiar pandas library. This is not the focus of this post. But let’s at least produce a nice visualisation with the data.
Wrapping up
We have only been touching the surface of SDMX and pandaSDMX. There is a lot more to explore and the pandaSDMX documentation is a good place to continue. Mastering SDMX in the Python ecosystem opens the door to working programmatically with data from official providers. This does not only facilitate the occasional data analysis, but is a prerequisite to building more complex applications and services with official data at scale.